在分類模型中,理解機器學習算法的性能是很重要的,以下我們先用二分類模型討論。一些有用的統計數字包括:
準確性(Accuracy):準確性是正確標記的機會比例,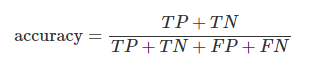
其中,TP是真正例的數量,TN是真負例的數量,FP是假正例的數量,FN是假負例的數量。
精度(Precision):精度是預測為正例中真正例的比例,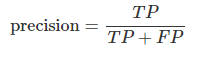
召回率(Recall):召回率是所有正例中真正例的比例,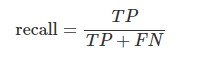
F1分數:對於分類應用,準確性可能不是一個足夠的分類評分。假設模型預測後,負例(標籤‘0’)比正例(標籤‘1’)多很多。在這種情況下,一個預測每個案例都是負例的分類器(他亂猜,啥給他都說是0)會有超高準確性,即使召回率=0且精度未定義。F1分數沒有這些缺點,採用的是評估分類器在精度和召回率等權重調和平均數: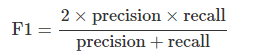
下表描述了二元分類的四個特殊且有問題的情況。F1分數在其中兩種情況下未定義。因此當Scikit-learn在沒有觀察到1或沒有預測到1的樣本上計算F1時,會print一個警告(UndefinedMetricWarning),並將F1值設為0。
| 條件 | 崩潰 | 準確性 | 精度 | 召回率 | F1分數 |
|---|---|---|---|---|---|
| 觀察到全部為1 | TN=FP=0 | =召回率 | 1 | [0,1] | [0,1] |
| 觀察到全部為0 | TP=FN=0 | [0,1] | 0 | NaN | NaN |
| 預測全部為1 | TN=FN=0 | =精度 | [0,1] | 1 | [0,1] |
| 預測全部為0 | TP=FP=0 | [0,1] | NaN | 0 | NaN |


 iThome鐵人賽
iThome鐵人賽